Jim Sterne disait, en parlant des web analytics : “Je sais ce que tu as fait l’été dernier. Mais je ne sais pas pourquoi.” Vingt ans plus tard, la réponse au pourquoi se trouve très vraisemblablement dans vos avis clients dans App Store, Google Play, ou Google My Business. Il manquait juste la méthode pour les connecter à vos données de conversion, avec l’aide d’un peu de machine learning. Accrochez-vous, on vous dit (presque) tout.
Et si vos problèmes de conversion étaient déjà documentés par vos utilisateurs ?
Imaginons la scène. Nous sommes lundi matin dans le bureau du directeur e-commerce d’une marque (pas si fictive que ça) de vente de boissons. Sa marque est présente via un réseau de points de vente physiques et propose sur son site Web et son application mobile un système d’achat et de réservation en ligne, type click and collect. Notre directeur e-commerce commence sa journée en consultant son dashboard analytics. Le taux de conversion de son application mobile est en baisse depuis six semaines. Les campagnes d’acquisition tournent à plein régime. Le budget est là. Les clics sont au rendez-vous. Mais quelque chose coince, juste là : entre le clic et l’achat.
La réponse, il ne la trouvera pas dans ses rapports d’acquisition dans GA, Piano, Matomo ou Piwik. Elle est ailleurs, “cachée” à la vue de tous, dans les 847 avis laissés sur les App Stores Google et Apple au cours des trois derniers mois. Elle est “planquée” dans les commentaires Google My Business de chaque point de vente physique. Elle attend, non lue, dans des champs texte publics, mais que personne n’a encore pensé à mettre en parallèle de données de performance.
Cette situation est malheureusement trop courante. Chez Empirik, nous vous proposons de creuser un peu plus loin dans cette mine d’or textuelle que représente tous les commentaires et les critiques des internautes.
Le problème : deux mondes de données qui s'ignorent
Dans cet exemple, la marque dispose d’un écosystème data relativement mature. GA4 est déployé sur le site Web et sur l’application mobile, avec un plan de marquage couvrant les micro-conversions (ajout au panier, sélection d’un point de retrait, création de compte) et les macro-conversions (commandes finalisées). Jusqu’ici tout va bien : classique.
Pourtant, un angle mort persiste: le feedback qualitatif des utilisateurs (voice of customer, VOC) n’était jamais mis en regard des données comportementales. Les avis App Store étaient “parfois” lus par le service client. Les commentaires Google My Business remontaient “parfois” jusqu’au marketing. Mais personne ne les croisait avec les événements GA4 pour identifier des comportements ou des tendances actionnables.
Le résultat ? Les décisions d’optimisation sont prises uniquement sur la base d’indicateurs quantitatifs : taux de chute/progression à chaque étape du funnel, temps moyen par page/écran, taux de rebond. Malheureusement, la dimension sémantique, qui aurait permis de comprendre le pourquoi et pas seulement le quoi, n’est pas visible dans la big picture.
Voyons comment renverser la tendance.
La méthode : bâtir un pont entre le texte et les événements
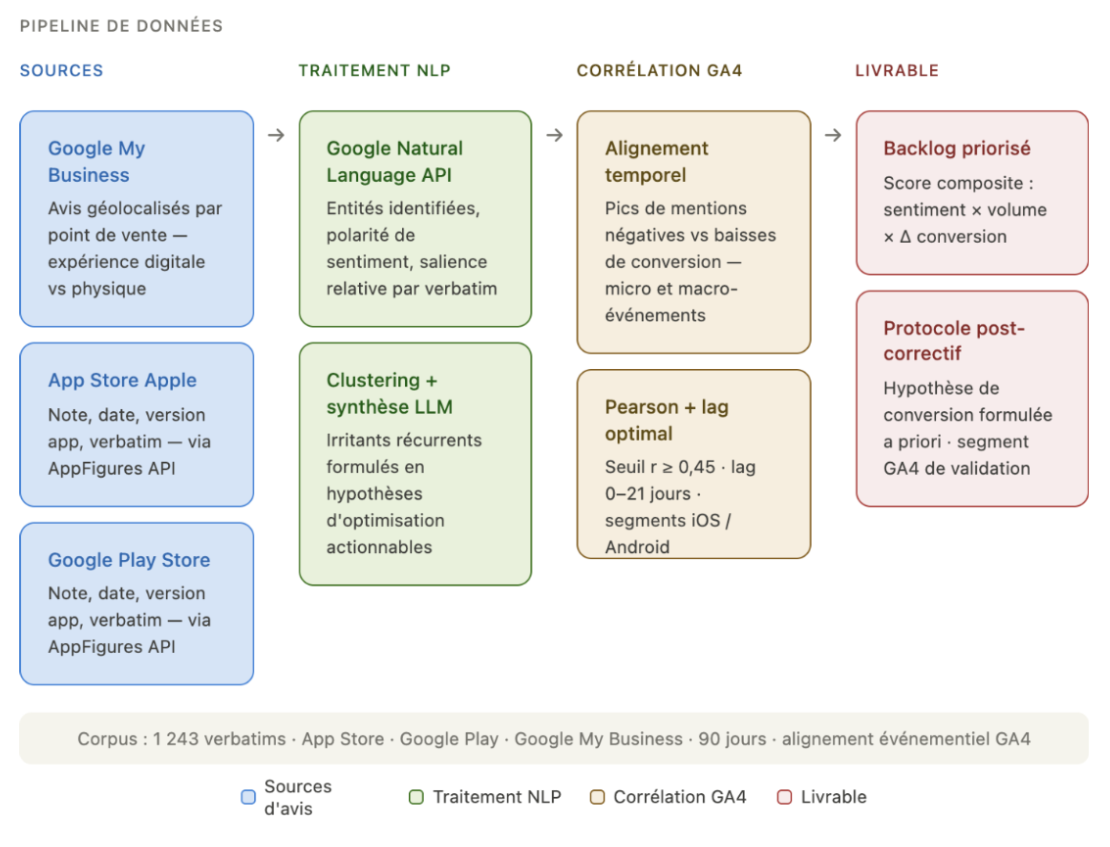
Je propose une approche qui s’articule autour de trois sources de données et d’un pipeline d’analyse en quatre étapes. Commençons par les sources de données.
Les sources de données
AppFigures permet d’extraire de façon structurée l’ensemble des avis déposés sur l’App Store Apple et le Google Play Store : note, date, version de l’app au moment de l’avis, verbatim complet. Pour Google My Business, l’API GMB permet de récupérer les avis géolocalisés par point de vente, en distinguant les avis mentionnant l’expérience digitale (commande en ligne, application) de ceux portant sur l’expérience physique (accueil, délais, disponibilité produit).
Votre solution digital analytics fournit le socle de mesure événementielle : clics et navigation, abandons par étape du funnel, segments d’utilisateurs sur base de leur comportement de conversion (ou pas), et cohortes d’acquisition liées aux campagnes.
Le pipeline d'analyse
Étape 1 : Extraction et nettoyage
Les verbatims (commentaires et critiques) sont:
collectés via les API respectives (Appfigures ou GMB),
normalisés (langue, ponctuation, doublons)
horodatés pour une synchro avec les dates des données analytics.
Étape 2 : Analyse
NLP
avec l'API Google Natural Language
Chaque verbatim est soumis à une analyse d’entités et de sentiments. L’API identifie les sujets mentionnés dans le texte (paiement, livraison, application, interface, compte utilisateur…) et leur polarité : est-ce que l’utilisateur en parle positivement, négativement, ou de façon neutre ? Avec quelle intensité ?
On obtient ainsi, pour chaque commentaire, une carte des irritants potentiels pondérés par leur importance relative dans le texte. On va pas se priver non plus : si l’API retourne des indices sur les commentaires positifs, on les regroupera plus tard dans des présentations dithyrambiques pour se faire mousser un peu 🙂
Étape 3 : Enrichissement par (L)LM
Le simple fait de dégager des entités brutes ou des topics (sujets) dans les verbatims ne suffit pas à générer des recommandations opérationnelles.
On fait donc tourner du machine learning ou un modèle de langage est invoqué sur des clusters de verbatims pour synthétiser les irritants récurrents, les qualifier par champ lexical selon leur impact perçu par l’utilisateur, et les formuler en termes compréhensibles pour des équipes produit et développement. C’est à cette étape que “paiement refusé sans raison” cesse d’être un tag NLP pour devenir un réel problème et donc une hypothèse d’optimisation documentée.
Étape 4 : Corrélation avec les événements analytics.
L’alignement de dates entre les pics de mentions négatives et les baisses de conversion sur des événements spécifiques est l’étape décisive. Une hausse des mentions négatives autour de l’expression “connexion au compte” pendant la semaine 14 coïncide-t-elle avec une hausse des abandons via les événements login_failed ou session_expired dans GA4 ? Si oui, la corrélation est documentée, quantifiée et intégrée au rapport d’optimisation.
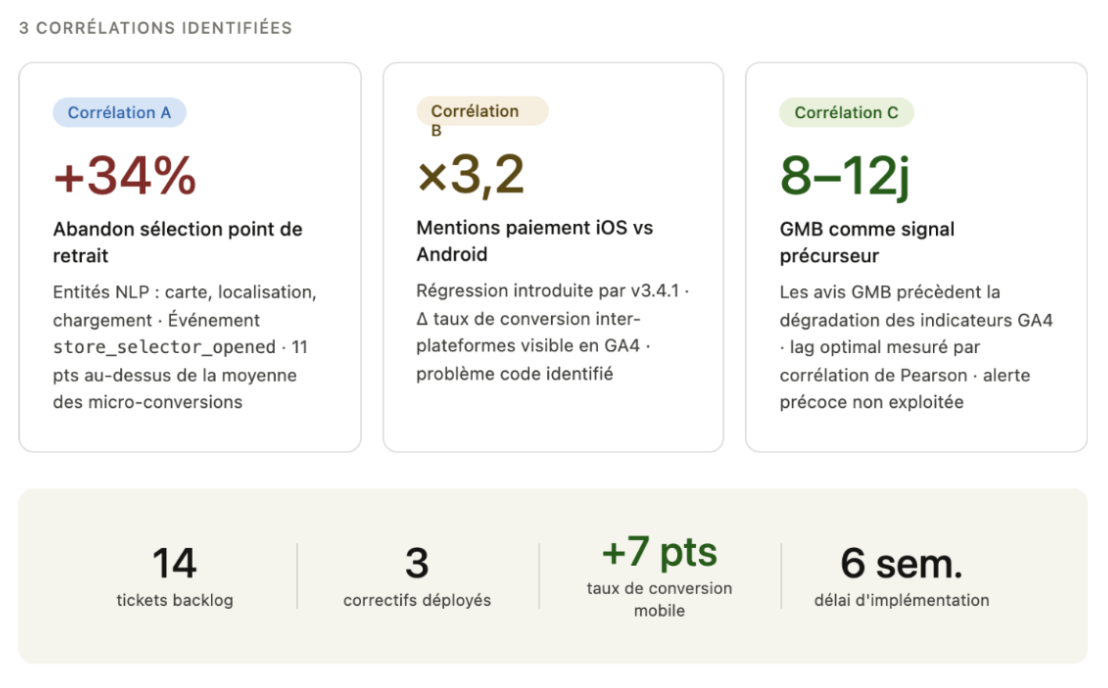
Les résultats : trois corrélations qui ont tout changé
L’analyse a porté sur un corpus de 1 243 verbatims (App Store, Google Play et GMB confondus) sur une période de 90 jours, croisée avec les données GA4 correspondantes.
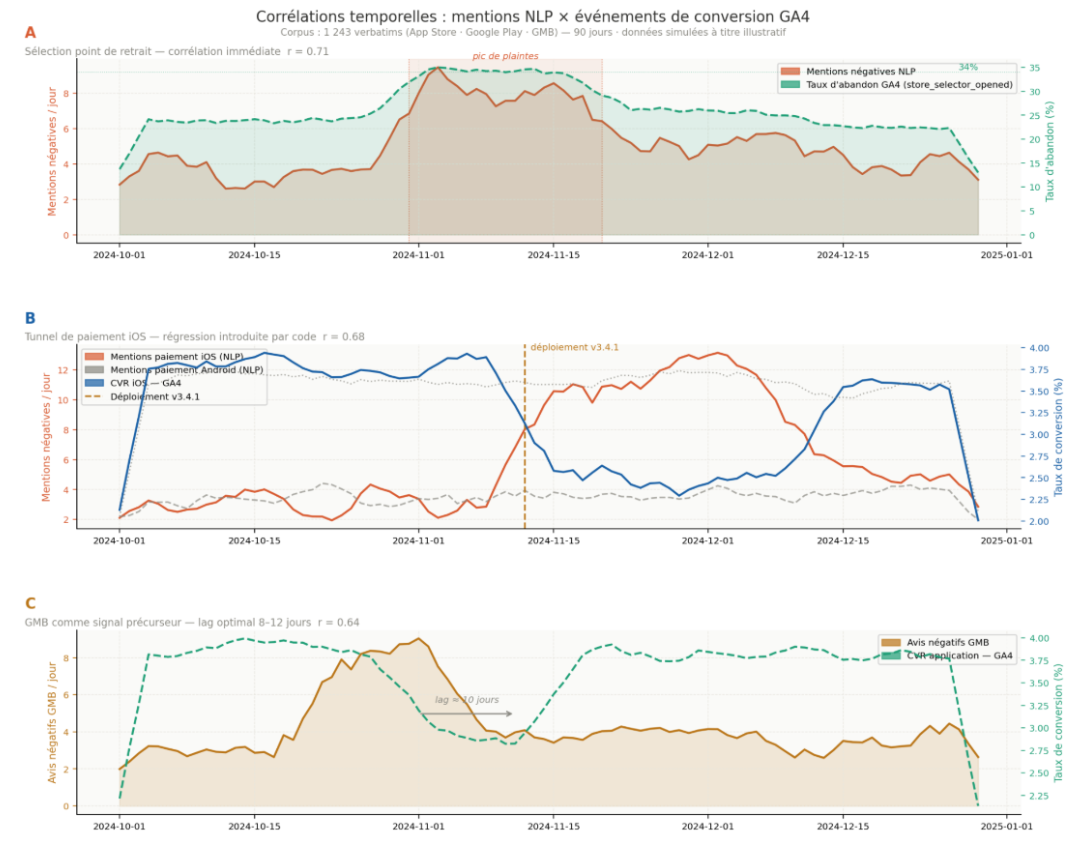
Corrélation A : L'écran de sélection du point de retrait.
L’API NLP a identifié un cluster autour des expressions “carte”, “localisation” et “chargement” avec un sentiment négatif dominant. Dans GA4, l’événement store_selector_opened présentait un taux d’abandon de 34 %, soit 11 points au-dessus de la moyenne des autres micro-conversions. En croisant les deux sources, il fallait bien l’admettre : l’écran de sélection du point de vente était perçu comme lent et peu lisible sur mobile, en particulier sur les appareils Android milieu de gamme (en regardant le modèle). Ce n’était pas un problème d’offre, c’était un problème de performance technique.
Cliquez sur le visuel
Corrélation B : Le tunnel de paiement sur iOS.
Les avis App Store pour la version iOS comprenaient 3,2 fois plus de mentions négatives autour de l’expression “paiement” que la version Android. En parallèle, GA4 montrait un écart de taux de conversion entre les deux plateformes qui s’était creusé depuis la mise à jour v3.4.1 de l’application iOS, déployée six semaines plus tôt. La corrélation de dates était nette : cette fois-ci, le problème n’était pas comportemental, il était lié au code.
Corrélation C : Les avis GMB comme signal précurseur.
La découverte la plus inattendue est venue de Google My Business où les commentaires négatifs sont arrivés 8 à 12 jours avant la dégradation des indicateurs GA4 correspondants. Les utilisateurs se plaignaient d’abord en point de vente (sur GMB), avant que le comportement négatif ne devienne visible statistiquement dans les données analytics de l’application. GMB fonctionnait comme un système d’alerte mais le signal était si faible que personne n’écoutait.
Cliquez sur le visuel
Cliquez sur le visuel
Le livrable : un plan d'optimisation orienté développement
La valeur d’une telle analyse ne réside pas dans les corrélations elles-mêmes, mais dans leur traduction opérationnelle. Un rapport adressé aux équipes techniques comprend :
Un backlog priorisé de 10+ points d’optimisation, classés grâce à un score qui combine l’intensité du sentiment négatif, le volume de mentions, et l’impact estimé sur le taux de conversion (basé sur le delta observé dans GA4).
Des fiches d’optimisation par ticket, chacune incluant : l’irritant identifié en langage utilisateur, les événements GA4 associés, les verbatims représentatifs anonymisés, et une suggestion d’implémentation technique. Attention à l’utilisation de l’IA, histoire de ne pas faire empirer les choses. 😱
Un protocole de mesure post-correctif : pour chaque optimisation déployée, une hypothèse de conversion est formulée avec un seuil de validation défini a priori. Après déploiement des correctifs, on observe la présence d’une inflection dans le nombre d’événements correspondant à chaque optimisation.
Ce dernier point est le plus souvent négligé et pourtant le plus décisif. Sans mesure rigoureuse des correctifs, on améliore sans savoir vraiment si on améliore. Le feedback qualitatif ouvre les hypothèses ; les données analytics valident ou invalidant les hypothèses.
Ce qui change concrètement
La plupart des équipes de marketing digital ont appris à optimiser sur base de ce que les données montrent. Elles savent lire un entonnoir, identifier une étape problématique, lancer un test A/B. En revanche, elles ont beaucoup plus de mal à écouter ce que les utilisateurs disent à propos de l’étape en question.
Connecter les avis clients (verbatims via Google My Business, App Store, Google Play) aux événements de conversion analytics, c’est réconcilier deux sources d’information que les équipes digitales ont longtemps traitées séparément : les indicateurs disent combien, les mots révèlent pourquoi.
Le NLP et les LLMs sont ici des accélérateurs, pas des oracles. Ils permettent de traiter à l’échelle ce qu’un humain ne pourrait pas lire en temps raisonnable. Mais fournir de la valeur analytique (identifier le pourquoi, ce qui compte, croiser les bons signaux, formuler les bonnes hypothèses) reste une compétence qui ne s’automatise pas avec de l’IA (pour l’instant).
Pour l’entreprise de vente de boissons, le résultat de l’optimisation devient concret : trois correctifs techniques déployés en moins de six semaines, un gain de 7 points de taux de conversion sur l’application mobile, et un dispositif de veille sémantique désormais intégré à la routine analytique de l’équipe.
Les avis ne sont plus lus après coup. Ils sont écoutés en continu. L’amélioration se mesure maintenant grâce aux événements, aux verbatims, et au score de satisfaction de l’application dans les app stores.
Pour aller plus loin
Vous avez des données analytics et une grande quantité de commentaires clients inexploités ? La mise en place d’un tel pipeline de données commence par un audit de vos sources disponibles et de votre plan de marquage existant, deux points de départ que nous évaluons systématiquement lors d’un premier cadrage.
Rassurez-vous, c’est souvent moins complexe qu’il n’y paraît. Et les enseignements, eux, valent plus que largement la peine 😉
Vous avez besoin d'aide pour traiter vos données Analytics ?