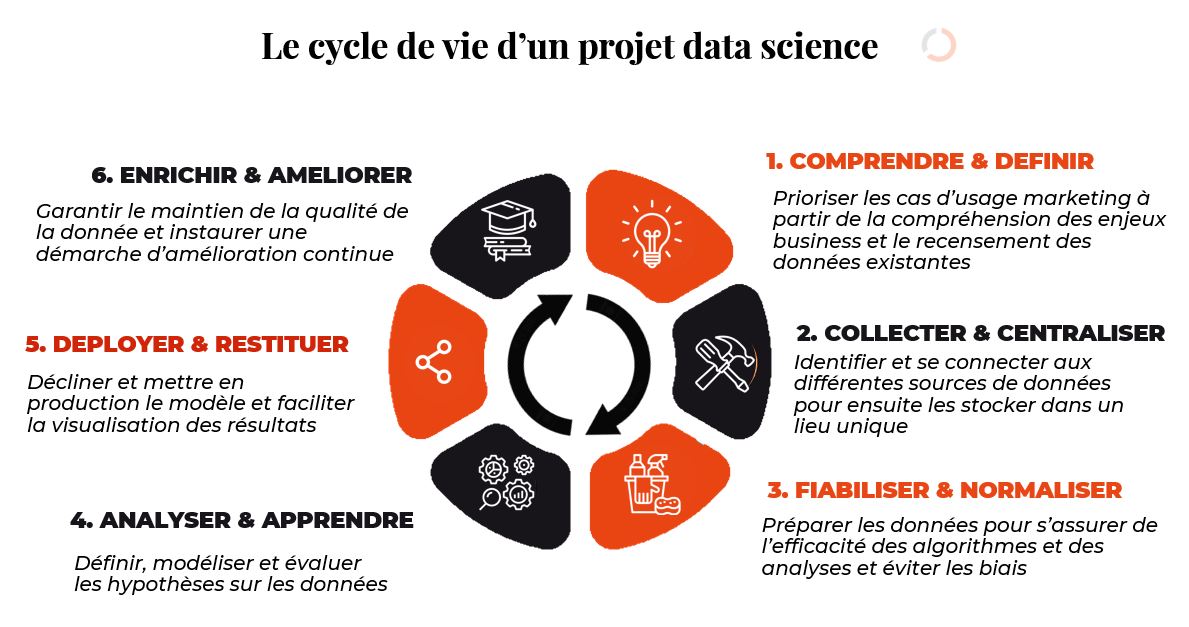
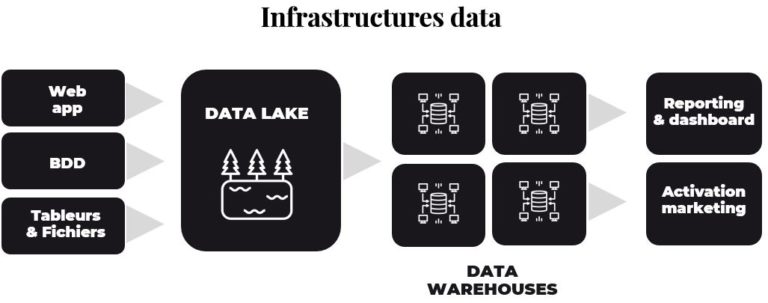
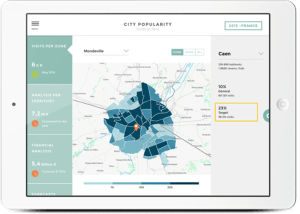
La Data Science, c’est un peu comme la Rolex à 50 ans. Si tu es une grande entreprise et que tu n’es pas en train de mener un projet IA, tu as un peu raté ta vie. Pourtant, les échecs sont nombreux. Nous vous livrons dans ce troisième article notre vision du cycle de vie d’un projet Data Science.