Principes
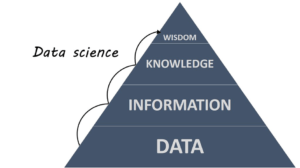
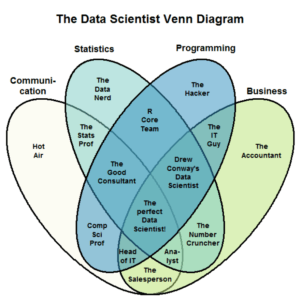
La Data Science est avant tout une approche multi-disciplinaire à l’intersection des mathématiques, statistiques, de l’analyse de données, de la théorie de l’information et de la programmation informatique qui a pour but d’extraire des connaissances à partir de données. L’utilisation de l’outil informatique permettant d’accéder à des connaissances inaccessibles à l’humain seul.
Le terme science est employé en référence à la création et l’utilisation historique de ces méthodes par la recherche fondamentale en mathématiques et informatique. L’idée d’origine de la méthode scientifique est de formaliser un process d’observation de la nature (ou les données) par le cycle Observation / Hypothèse / Expérimentation / Analyse des résultats / Observation…
L’un des points étant également de formaliser les expériences, donc les algorithmes et les données qu’ils manipulent, pour faciliter la réplication des expérimentations et la comparaison des résultats.
L’objectif du data scientist est toujours la modélisation d’un système, avec les motivations principales suivantes : automatisation, contrôle des risques/erreurs, prédiction, classification.
Par modélisation, on entend la représentation mathématique d’un phénomène, c’est à dire la création une relation mathématique entre des valeurs mesurées en relation avec le phénomène.
Par exemple, si vous étudiez le trafic quotidien sur votre site web, vous disposez de nombreux indicateurs fournis par vos outils. Le modèle va tenter d’établir une relation mathématique entre ces indicateurs pour vous permettre de prédire le trafic futur.
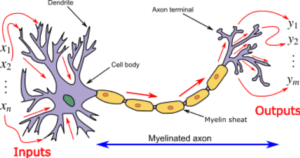
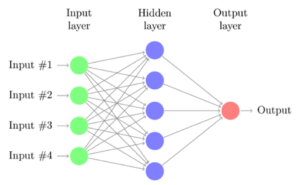
Un modèle accepte en entrée (inputs) un ensemble de données observées, typiquement vos indicateurs préférés.
Il produit en sortie une réponse désirée (output) qui peut être comparée à une valeur attendue (apprentissage), ou qui est utilisée pour prédire le comportement du phénomène (inférence).
Dans le cadre de la modélisation statistique, la relation mathématique définie entre les variables décrit certaines propriétés statistiques d’un échantillon de données. L’idée étant que l’hypothèse confirmée par l’échantillon puisse se généraliser à la population.
Par exemple, vous avez créé un modèle se basant sur les 3 dernières années de données Analytics. Vous espérez que les conclusions pourront se généraliser aux jours à venir.
Méthode
Le data scientist va donc identifier les données d’intérêt, les normer, mettre en place des systèmes de récolte, stockage et agrégation de données (ETL, APIs, data warehouses/ data lakes, etc.). Sur les projets de grande envergure, ces tâches sont dévolues à des spécialistes de l’infrastructure et de l’architecture des données (data engineers)
Le data scientist va enfin envisager les méthodes d’analyse puis préparer les données avant l’application des algorithmes.
Il peut également être épaulé à ce niveau par des ingénieurs spécialisés dans l’optimisation des algorithmes, notamment par leur parallélisation sur plusieurs machines pour en accélérer l’exécution.
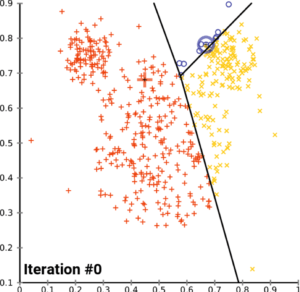
La boîte à outil du data scientist va couvrir un spectre s’étendant des statistiques descriptives standards (oui, même la moyenne et l’écart-type…) jusqu’aux méthodes les plus avancées (apprentissage automatique, réseaux de neurones artificiels, inférence bayésienne, arbres de décision…) en passant par la visualisation de données.
Il a donc à minima des connaissances en mathématiques, statistiques, développement, informatique fondamentale, manipulation de données, et en visualisation.
Le data scientist est également un data analyst, la plupart du temps. Au delà de la boîte à outil de méthodes où il pioche selon les problèmes à résoudre, il est capable d’en analyser les résultats, d’extraire des patterns en vue de prédictions futures, de sélectionner les variables d’intérêt (features) et de tirer des informations depuis les sources de données à sa disposition.
Un bon data scientist n’est pas celui qui maîtrise parfaitement l’intégralité des méthodes, algorithmes et théories possibles, mais bel et bien celui qui les connaît assez pour choisir la méthode la plus à même de résoudre le problème avec les données dont il dispose.