Suivre les mentions d’une marque dans des outils comme ChatGPT ou Perplexity, ça semble simple sur le papier, mais en réalité… c’est loin d’être fiable. Les réponses des LLM varient énormément d’un compte à l’autre, d’un jour à l’autre, même avec les mêmes questions. Chez Empirik, on a mené une petite étude interne sur le sujet, et les résultats sont parlants : entre volatilité des réponses, mémorisation aléatoire et impossibilité de suivre les positions, il faut revoir complètement la façon de faire. On vous partage ici nos constats et quelques bonnes pratiques pour un suivi plus solide.
Pourquoi cette étude ?
Les Large Language Models (LLM) comme ChatGPT transforment l’accès à l’information. Mais peut-on suivre les mentions de marques ou d’entreprises aussi facilement que sur le web traditionnel ? Nous avons mené une étude pour explorer la volatilité des réponses et les défis du monitoring sur ces nouvelles plateformes.
Notre méthodologie
Nous avons analysé les réponses de ChatGPT à une série de prompts
Sur 20 “vrais” comptes ChatGPT utilisés au quotidien par des collaborateurs d’Empirik avec un fort historique sur les sujets du marketing digital
Couvrant 2 thématiques : la recherche d’hôtel et la recherche d’agences digitales
Avec 2 types de prompts : “Classiques” (type recherche par mots-clés sur Google) et “Contextuels IA” (mises en situation).
Exemple de prompts
Prompts classiques
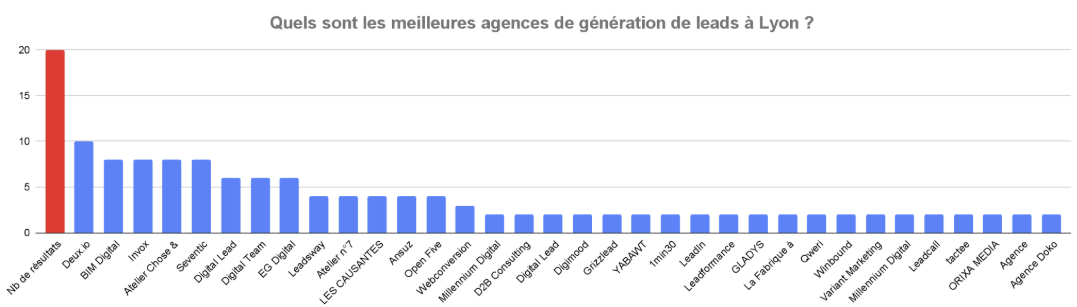
Digital : “quelle est la meilleure agence de génération de leads à Lyon ?”
Hotel : “quels sont les meilleurs hôtels à Chamonix pour un séminaire ?”
Prompts contextuels IA
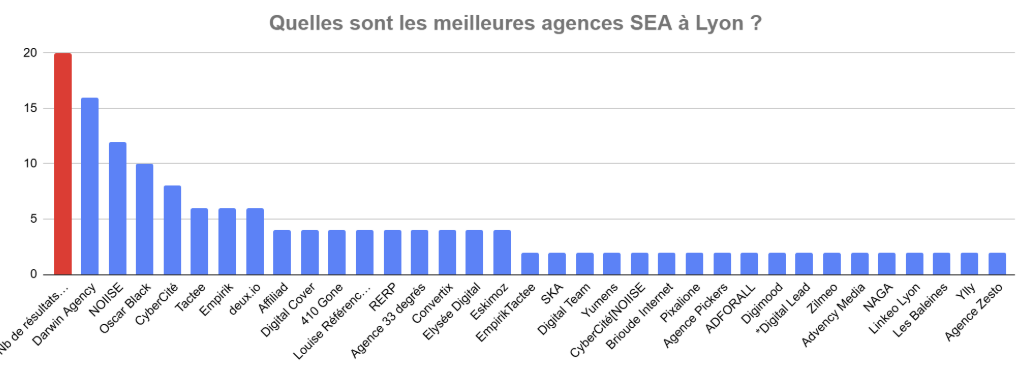
Digital : “Je suis le directeur e-commerce d’une entreprise qui fabrique des pièces automobiles. Mon site utilise le CMS Shopify. Je suis la recherche d’une agence analytics basée à Lyon qui pourrait m’aider à déployer la solution GA4 en server side.”
Prompts contextuels IA
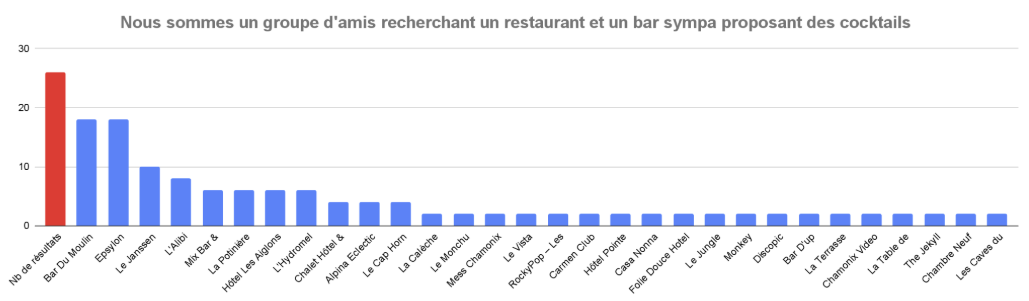
Hôtel : “Nous sommes un groupe d’amis ayant entre 30 et 35 ans et habitant à 30 kms de Chamonix. Nous cherchons un restaurant et un bar sympa proposant des cocktails. Nous sommes 6. Que proposes tu ?”
Métriques et traitements
Similarité des résultats : Indice de Jaccard moyen par prompt.
Stabilité des positions : Coefficient de Kendall Tau
Diversité des entités : Pourcentage d’entités uniques (apparaissant une seule fois par prompt).
Analyse comparative : Par thématique et par type de prompt.
Normalisation : Regroupement des variantes de noms d’entités pour une analyse cohérente.
Limites de l’étude
Taille de l’échantillon : L’analyse porte sur 12 prompts. Des tendances observées pourraient évoluer avec un corpus plus large.
Instantanéité : Les résultats des LLMs sont dynamiques. Cette analyse est une photographie à un instant T.
Normalisation des entités : Bien que rigoureuse, elle peut toujours comporter des imperfections face à la créativité lexicale des LLMs.
Enseignement N°1 :
Une volatilité extrême des résultats
Pour un même prompt, les réponses des LLMs varient considérablement d’une session à l’autre.
La preuve en chiffres
Seulement 14.60% de similarité moyenne (Indice de Jaccard) entre les listes d’entités pour un même prompt. Cela signifie qu’en moyenne, seulement 14.60% des entités sont communes entre les listes de résultats pour un même prompt.
En moyenne, 63.33% d’entités uniques apparaissant une seule fois sur l’ensemble des résultats pour un même prompt !
Ces chiffres illustrent sans équivoque la difficulté d’obtenir des résultats cohérents et reproductibles, ce qui est un défi majeur pour le tracking des mentions.
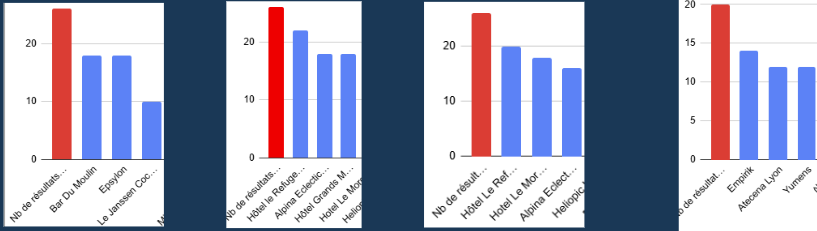
Un exemple pour illustrer
34 entités différentes sont citées sur 26 résultats
18 entités sur 34 (soit 53%) ne sont citées qu’une fois
2 entités réussissent à être citées dans près de 70% des réponses mais le pourcentage chute ensuite assez vite : 38%, 31%, 23%, etc
Des constats identiques quels que soient les prompts ou les thématiques
Le taux de présence moyen et médian 55% pour le top 3 des entités
Si nous constatons une très forte volatilité des résultats au global, certaines entités arrivent à se détacher
Le top 3 des entités de chaque prompt a un taux de présence moyen et médian de 55%.
Pour le top 1, le taux de présence moyen grimpe à 68%.
Un taux de présence de 50% pourrait ainsi être considéré comme le seuil minimal d’une bonne visibilité sur un LLM.
Enseignement N°2 :
La mémorisation accentue la volatilité des résultats
La volatilité est encore plus marquée pour les prompts dont la thématique a été “mémorisée” par Chat-GPT
La preuve en chiffres
Si l’indice de similarité (Jaccard) est de 14,60% au global, il n’est que de 11,42% pour les prompts de la thématique Digital.
Au-delà de la volatilité, on observe une dispersion plus forte sur les résultats des prompts de la thématique digitale : le pourcentage d’entités uniques par prompt est de 68,96% pour la thématique Digital contre 57,71% pour la thématique Hôtel.
Dans la même logique, le nombre d’entités moyen par résultat est beaucoup plus élevé pour la thématique Digital (15,4) contre 12,1 pour la thématique Hôtel.
L’effet mémorisation
Ces résultats plus volatiles et disparates pourrait s’explique par l’effet mémorisation des LLM.
Les LLMs comme Chat-GPT s’appuient sur la mémoire à court terme des conversations mais aussi les éléments importants des conversations passées pour personnaliser leurs réponses.
Webinar
Google Leak : réconcilier SEO, UX et CRO grâce à la data
Une volatilité encore plus marquée pour les prompts “contextuels IA”
Les prompts que nous avons appelés “Contextuels IA” sont beaucoup plus détaillés et précis que les prompts classiques qui pourraient s’apparenter à une recherche SEO sur Google.
L’indice de similarité de leur résultats est beaucoup plus faible (12,68% contre 16,51% pour les prompts classiques). Leur pourcentage d’entités uniques par prompt est aussi plus élevé (69,90% contre 56,77%).
Ce résultat suggère une exploration plus large et moins consensuelle de la part du LLM.
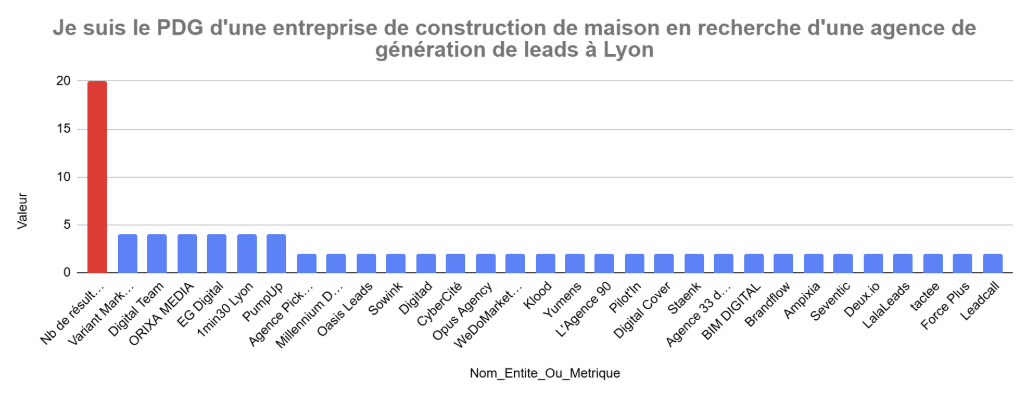
Dans certains cas, la mémorisation modifie complètement la structure de la réponse
Exemple sur ce prompt : “Je suis le PDG d’une entreprise de construction de maison. Je suis à la recherche d’une agence de marketing digital lyonnaise capable de générer des leads”
Un résultat sur un compte d’un expert Analytics suggère des solutions : “Analyzify est une application Shopify dédiée à l’intégration avancée de GA4, offrant une solution clé en main pour le suivi des données...”
Un résultat sur un compte d’un consultant SEO propose : “En tant que directeur e-commerce d’une entreprise spécialisée dans les pièces automobiles et utilisant Shopify, vous recherchez une agence analytics basée à Lyon pour vous accompagner dans le déploiement de Google Analytics 4 (GA4) en mode server-side. Voici quelques agences lyonnaises reconnues pour leur expertise dans ce domaine : “
Enseignement N°3 : Le suivi de positions ? On oublie !
Dans les rares cas où les entités sont communes entre les mêmes résultats, leur ordre d’affichage varie énormément.
Un ordre d’affichage très instable
L’étude met en lumière une très forte instabilité des l’ordre d’affichage des positions.
Le coefficient de Kendall Tau moyen qui mesure la similarité de l’ordre de classement de 2 variables est de 0. Une valeur de 0 indique une absence d’association ou de corrélation entre les classements.
Un suivi de position d’une mention sur un LLM n’a donc aucune intérêt. Il est donc préférable de se concentrer sur le taux de présence comme indicateur de référence de suivi des mentions.
Comment tracker les mentions sur les LLMs intelligemment ?
Une méthode de tracking à adapter
Il est impossible d’abandonner le tracking des mentions sur les LLMs , surtout pour une agence SEO , étant donné l’importance croissante de l’analyse de la visibilité d’une marque au sein des résultats IA.
Les résultats SEO sur Google sont également volatiles car ils sont personnalisés selon l’historique, la localisation, le profil, etc. Mais nous n’avons jamais observé une telle variabilité des résultats qui pourrait remettre en cause la fiabilité de suivi des positions.
La volatilité des LLMs est telle que les méthodes traditionnelles de tracking doivent être adaptées.
Les gardes-fous à déployer
➡️On multiplie les interrogations d’un même prompt sur un LLM en variant les conditions de modèle (GPT4o, mini, etc) et de mémoire (aucune mémoire, mémoire très spécialisée, etc)
➡️ On calcule le taux de présence et on oublie la notion de position.
➡️ On considère qu’un bon taux de présence est à minima de 50%. Il pourrait correspondre à une visibilité en top 3 sur Google.
➡️ Un taux de présence de 70% pourrait matérialiser une visibilité optimale équivalente à une 1ère position SEO.
Vous souhaitez améliorer le tracking de vos mentions sur les LLMs ?