Une expression régulière (Regular Expression, souvent abrégée en regex ou RegEx et plus rarement expression rationnelle) décrit un motif,
un pattern que nous souhaitons rechercher et localiser dans du texte (y compris des chiffres)
.
Ce motif a pour but d’analyser du texte qui a été encodé numériquement sous forme de “chaîne de caractères” (string en VO).
Le terme “caractère” employé ci-après désigne n’importe quel élément du texte ainsi encodé : les lettres et chiffres mais également les espaces, signes de ponctuation et autres sauts de lignes ou tabulations. Chacun des éléments possède un symbole nous permettant de l’identifier et de l’utiliser dans notre pattern.
Les caractères spéciaux
Une expression régulière est construite à partir de caractères dits “réservés”, possédant chacun un sens particulier qui permettent de définir différents comportements de recherche sur les patterns.
Par défaut, une regex est sensible à la casse :
a ≠ A
Voici les caractères réservés les plus courants et leur signification :
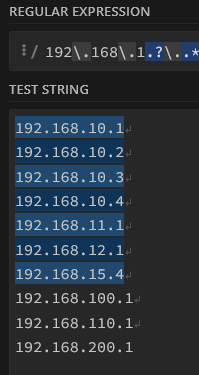
^
$
.
?
*
+
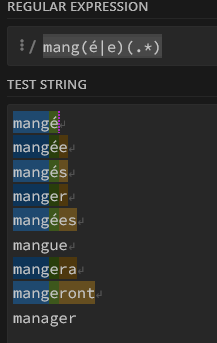
()
-
Capture un groupe de caractères dans l’ordre
-
La variante (?:) permet le matching sans capture
-
Permet la réutilisation des valeurs repérées (search & replace, filtre GA…)
-
(abc) ne repère pas acb mais uniquement abc
-
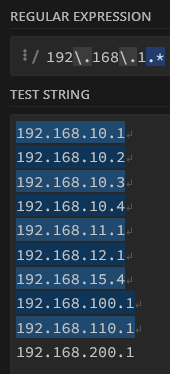
Pro-Tip : (.*) désigne donc n’importe quelle combinaison de caractères, y compris la chaîne vide
{}
-
Nombre de caractères
-
S’applique au caractère précédent ou au groupe ()
-
1 seul chiffre {n} : le caractère ou groupe apparaît exactement n fois
-
2 chiffres {n,m} : apparaît au moins n fois et au plus m fois
[]
-
Ensemble de caractères (individuels)
-
[abc] repère acb (et abc et cba, etc.)
-
Attention, un ^ dans un [] ne représente pas le début de chaîne, mais une négation
-
Certains caractères spéciaux perdent leurs signification dans un ensemble
-
On peut utiliser le tiret comme raccourci : [0-9], [A-Z], [0-9A-Za-z]
|
\d et \D
\w et \W
-
w représente n’importe quel caractère alphanumérique
-
Donc \w+ représente tous les “mots” d’une chaîne (= les éléments séparés par un espace, une tabulation, un saut de ligne…)
-
W représente n’importe quel caractère ni chiffre, ni lettre
\s et \S
-
s représente n’importe quel signe invisible d’espacement (espace, tabulations…)
-
S représente n’importe quel caractère qui n’est pas un espacement
L’échappement
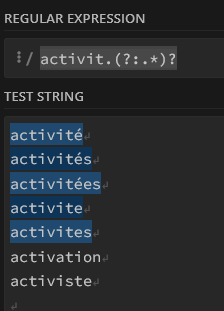
Que se passe-t-il si vous recherchez un point dans votre texte ? Ce caractère réservé est un “joker” : il sert à identifier n’importe quel caractère dans le texte !
Le mécanisme permettant de rechercher un caractère réservé dans une chaîne s’appelle “échappement” (faute de meilleure traduction).
Ça consiste tout simplement à ajouter un anti-slash \ (oui ce caractère que vous n’utilisez jamais : alt Gr+8 sous Windows ou Alt + Maj + / sous MacOS) devant votre point : \.
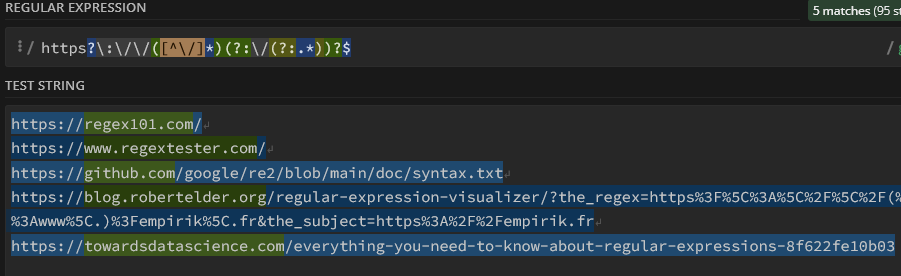
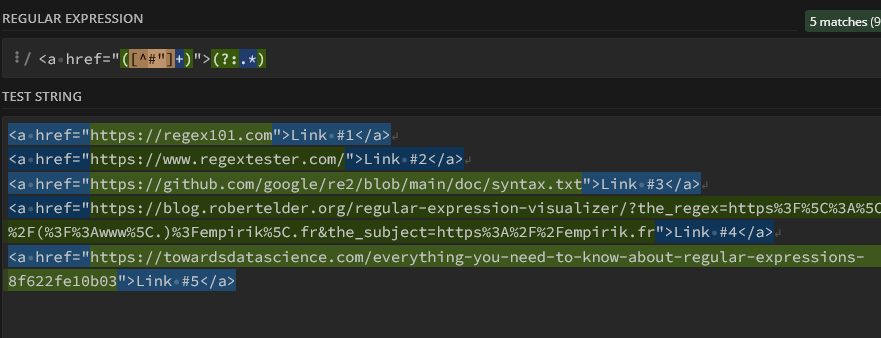
Ce mécanisme doit être utilisé dès que vous recherchez un caractère réservé. Vous allez beaucoup le rencontrer pour les matching sur des urls, par exemple à cause des slashes et des points, omniprésents.
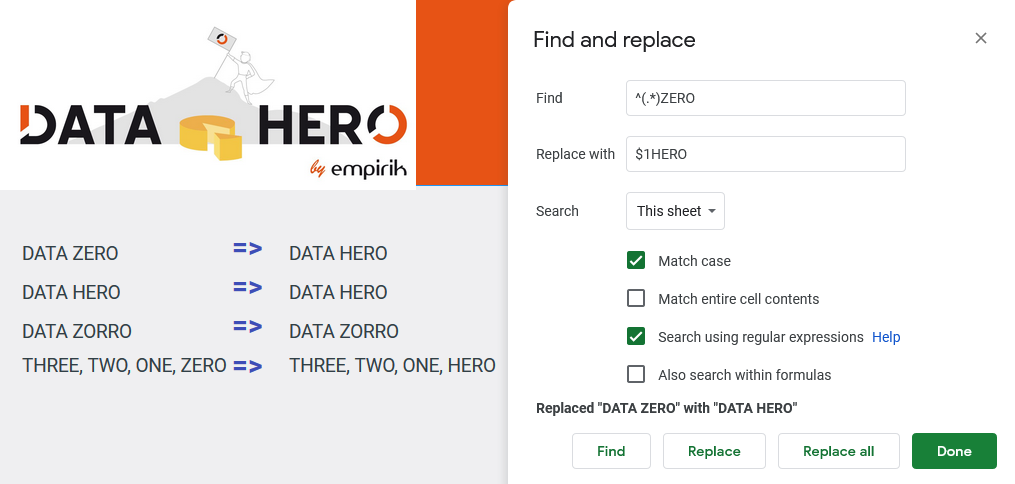
L’extraction des motifs et patterns
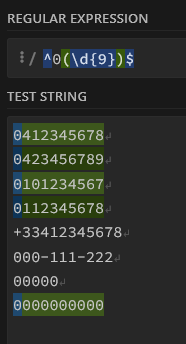
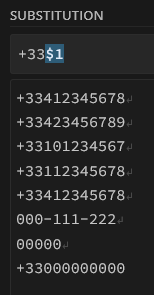
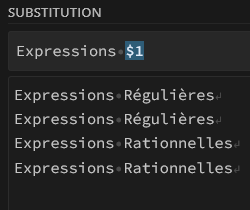
La plupart des outils vous permettent de récupérer la (ou les) valeurs trouvée par votre regex (à l’aide d’un groupe parenthèsé () )pour la réutiliser, typiquement dans un rechercher/remplacer. Le plus souvent, la 1ere valeur repérée sera désignée sous le terme $1, la seconde $2, etc. (c’est le cas pour Gsheets, GA, etc.)
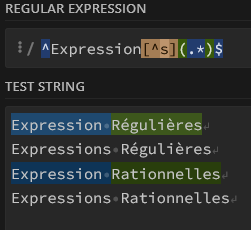
Ainsi, imaginons vouloir corriger les fautes du texte ci-dessous :
- Expression Régulières
- Expressions Régulières
- Expression Rationnelles
- Expressions Rationnelles
Pour corriger les erreurs et passer au pluriel, nous devons :
-
remplacer toutes les occurrences de Expression par Expressions
-
mais pas les occurrences d’Expressions sinon on obtiendrait “Expressionss” !
-
et conserver la suite de la chaîne.
On cherchera ainsi
^Expression[^s](.*)$
Que l’on remplacera par
Expressions $1
Ici $1 se réfère à la fin de la chaîne, capturée par (.*)$, donc tout ce qui est situé après Expression (sans ‘s’) dans lignes 1 et 3 de notre texte. Les lignes 2 et 4, sans faute d’orthographe, seront ignorées par notre regex.